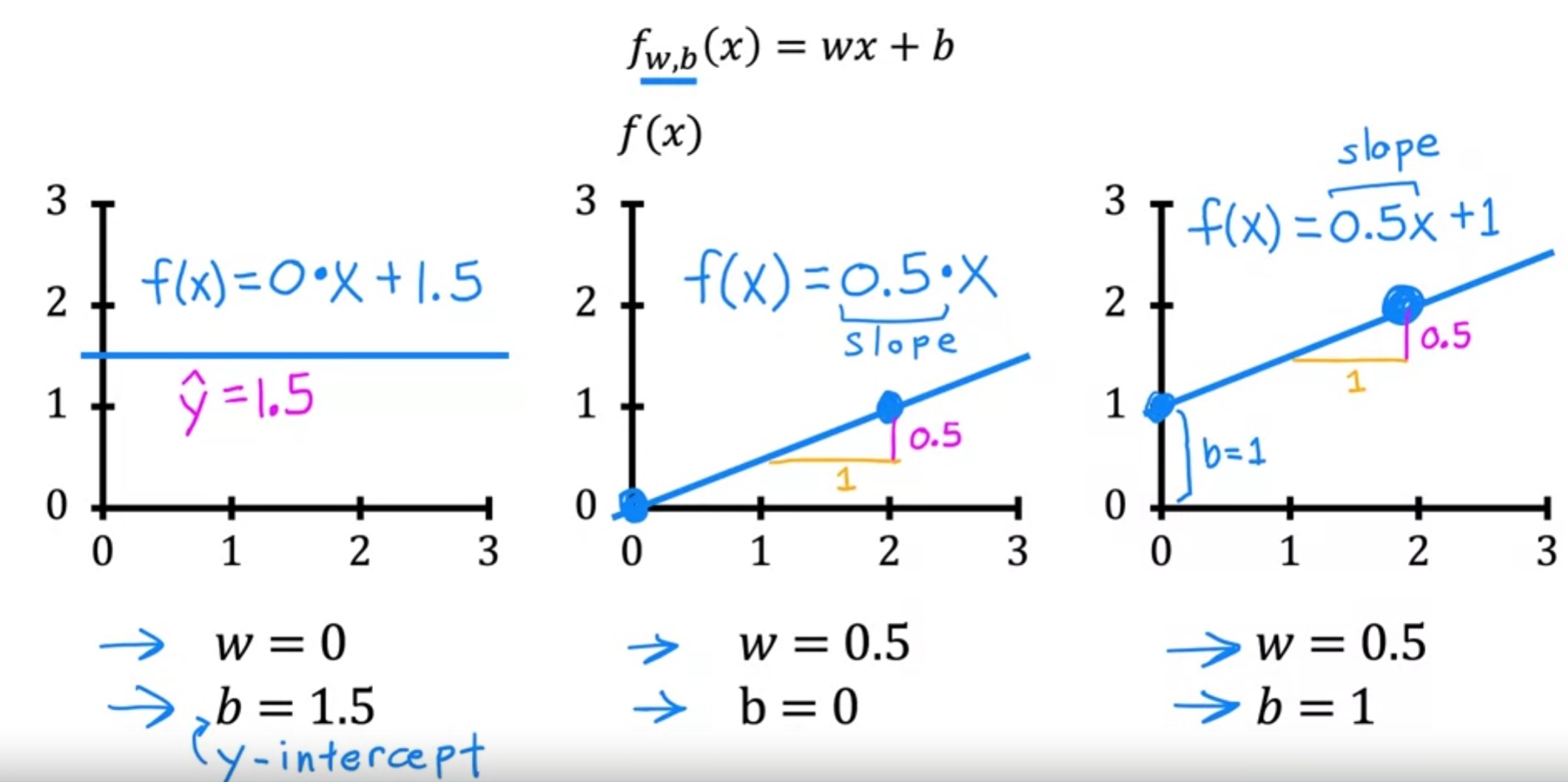Supervised Machine Learning - Regression and Classification
Overview
- Supervised learning, refers to algorithms that learn x to y or input to output mappings.
- The key characteristic of supervised learning is that you give your learning algorithm examples to learn from. That includes the right answers, whereby right answer, I mean, the correct label y for a given input x, and is by seeing correct pairs of input x and desired output label y that the learning algorithm eventually learns to take just the input alone without the output label and gives a reasonably accurate prediction or guess of the output.

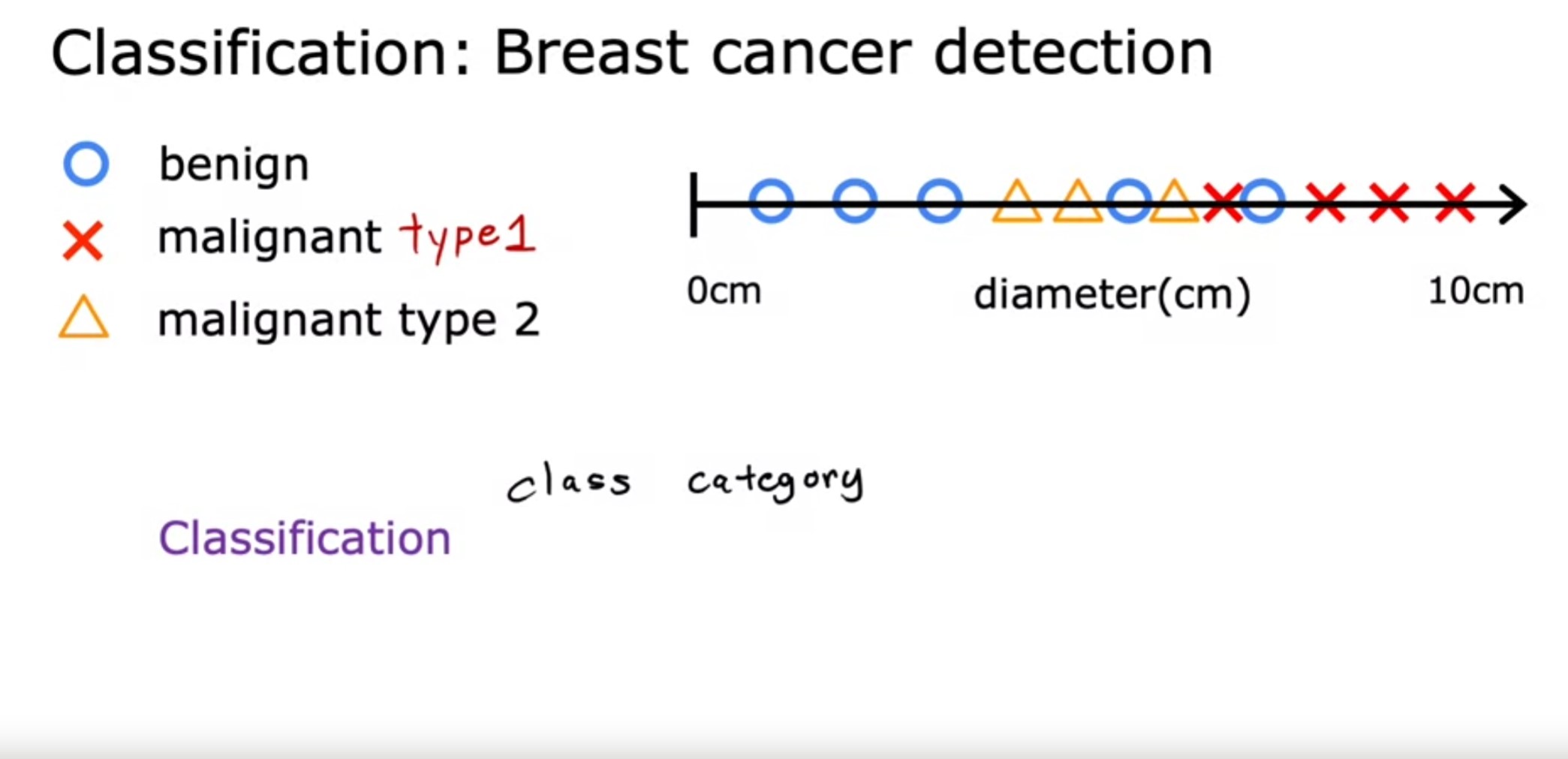
- One reason classification is different from regression is that we’re trying to predict only a small number of possible outputs or categories. In this case two possible outputs 0 or 1, benign or malignant. This is different from regression which tries to predict any number, all of the infinitely many number of possible numbers.
-
In a regression application like predicting prices of houses, the learning algorithm has to predict numbers from infinitely many possible output numbers. Whereas in classification the learning algorithm has to make a prediction of a category, all of a small set of possible outputs.
-
Clustering algorithm. Which is a type of unsupervised learning algorithm, takes data without labels and tries to automatically group them into clusters.
-
in unsupervised learning, the data comes only with inputs x but not output labels y, and the algorithm has to find some structure or some pattern or something interesting in the data.
-
One is called anomaly detection, which is used to detect unusual events. This turns out to be really important for fraud detection in the financial system, where unusual events, unusual transactions could be signs of fraud and for many other applications.
-
The third unsupervised learning is to learn about dimensionality reduction. This lets you take a big data-set and almost magically compress it to a much smaller data-set while losing as little information as possible.
Terminology

Linear Regression with One Variable
- Also called univariate linear regression
- The idea is to fit a straight line to the data
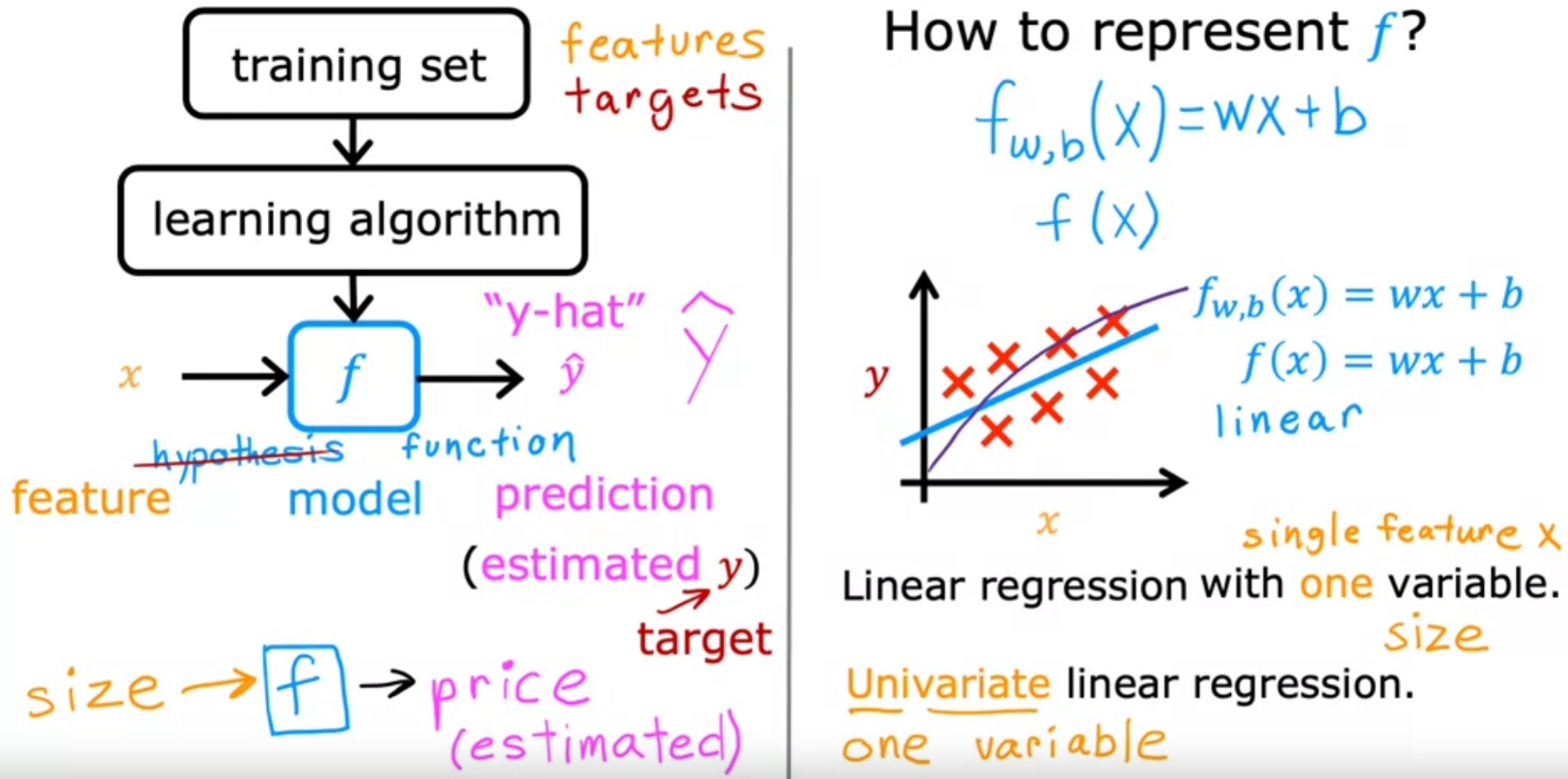
- To train the model, you feed the training set, both the input features and the output targets to your learning algorithm.
- Then your supervised learning algorithm will produce some
function. - We’ll write this function as lowercase f, where f stands for
function. Historically, this function used to be called a
hypothesis,. The function f is called the model. - A key question is, how are we going to represent the function f? Or in other words, what is the math formula we’re going to use to compute f?
- For linear regression, to fit the straight line, the formula is
\begin{equation} f_w,_b(x) = wx + b \end{equation}
Cost Function
- w, and b are the parameters to the model or coefficents or weights.
- These are the variables that can be adjusted during training inorder to improve the model.
bis also called the y intercept because that’s where it crosses the vertical axis or the y axis on this graph.