Tokenization
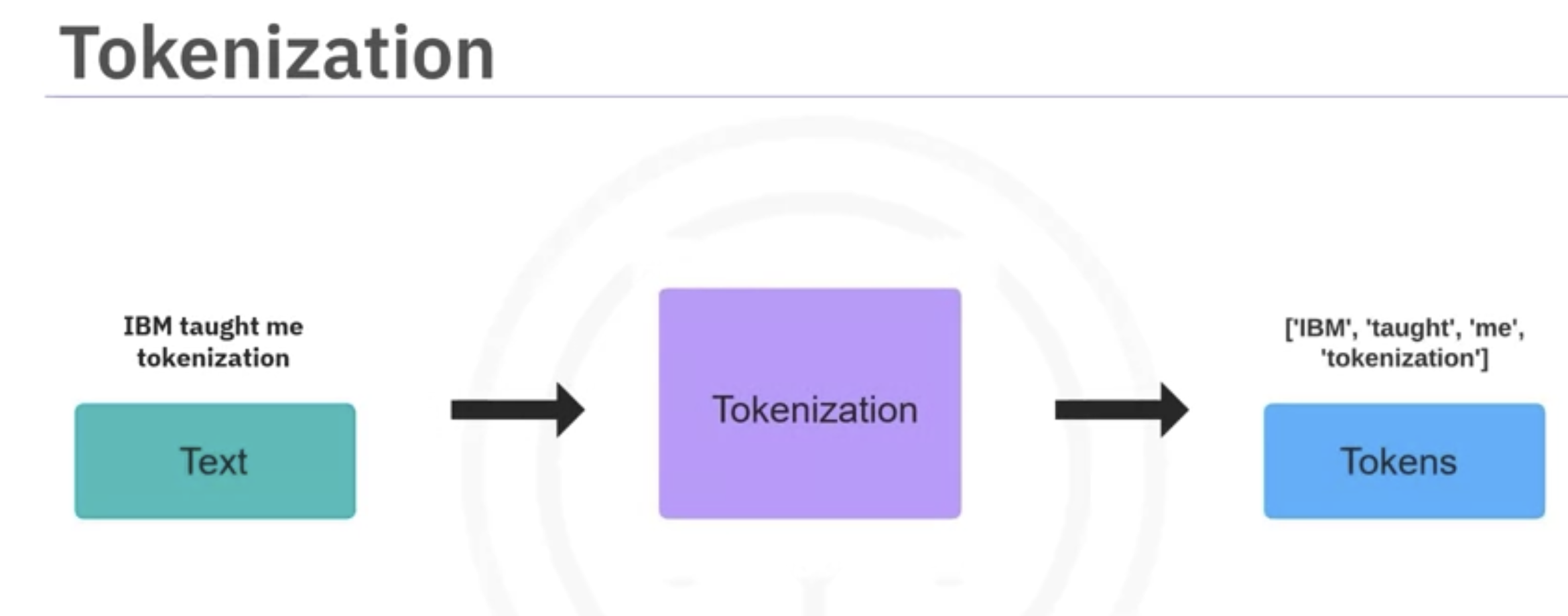
- The process of breaking a sentence into smaller pieces, or tokens, is called tokenization.
- The tokens help the model understand the text better. For a sentence like, IBM taught me tokenization, tokens can be IBM, taught, me and tokenization.
- Different AI models might use different types of tokens. The program that breaks down text into individual tokens is called a tokenizer.
- Tokenizers generate tokens primarily through three tokenization methods, word based, character based, and subword based.
-
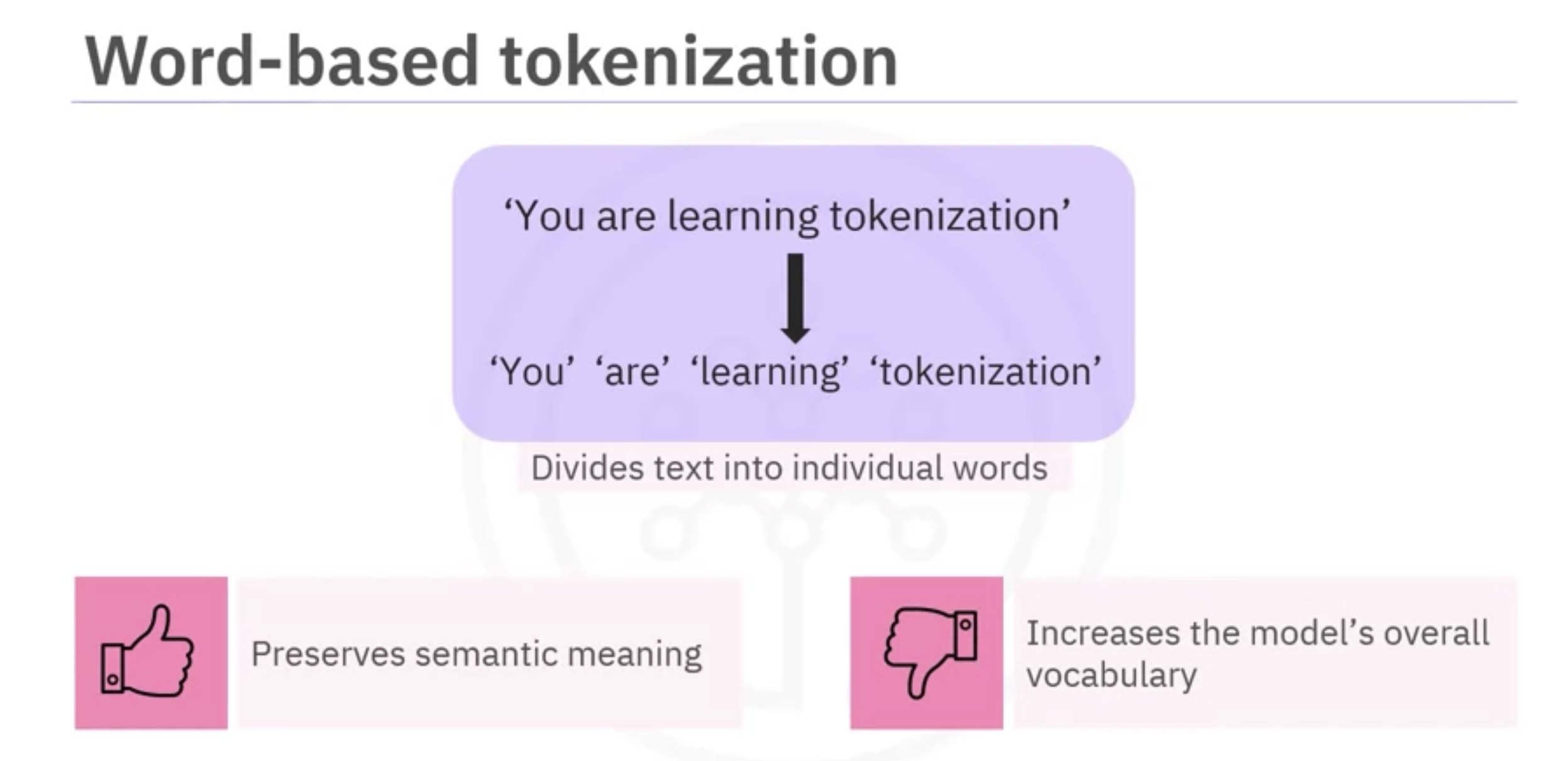
- word based tokenization: the text is divided into individual words, each word considered a token.
- An advantage of word based tokenization is that it preserves the semantic meaning.
- A disadvantage is that treating each word as a token significantly increases the model’s overall vocabulary.
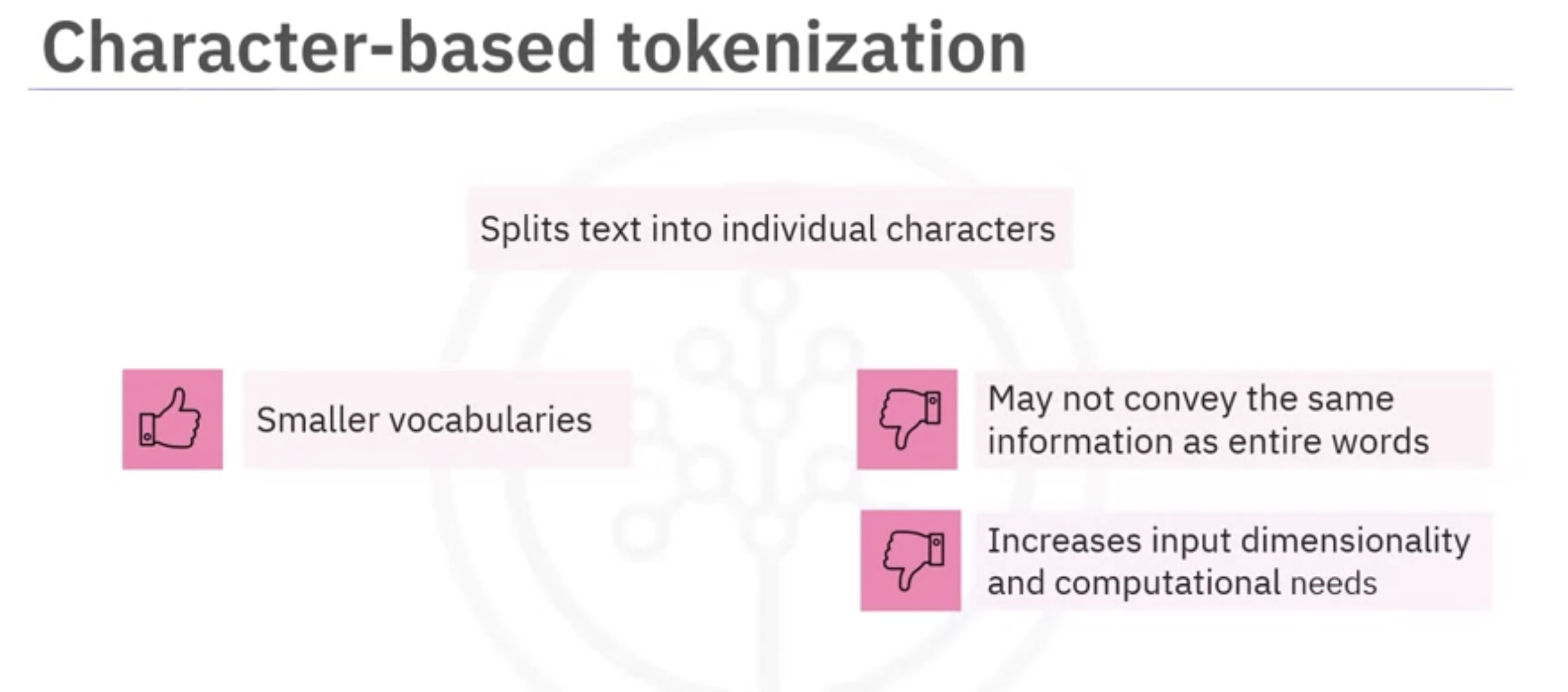
- character based tokenization: involves splitting text into individual characters.
- Advantage: the vocabularies are small.
- Disadvantage: single characters may not convey the same information as entire words. Each character as a unique token increases input dimensionality and computational needs.
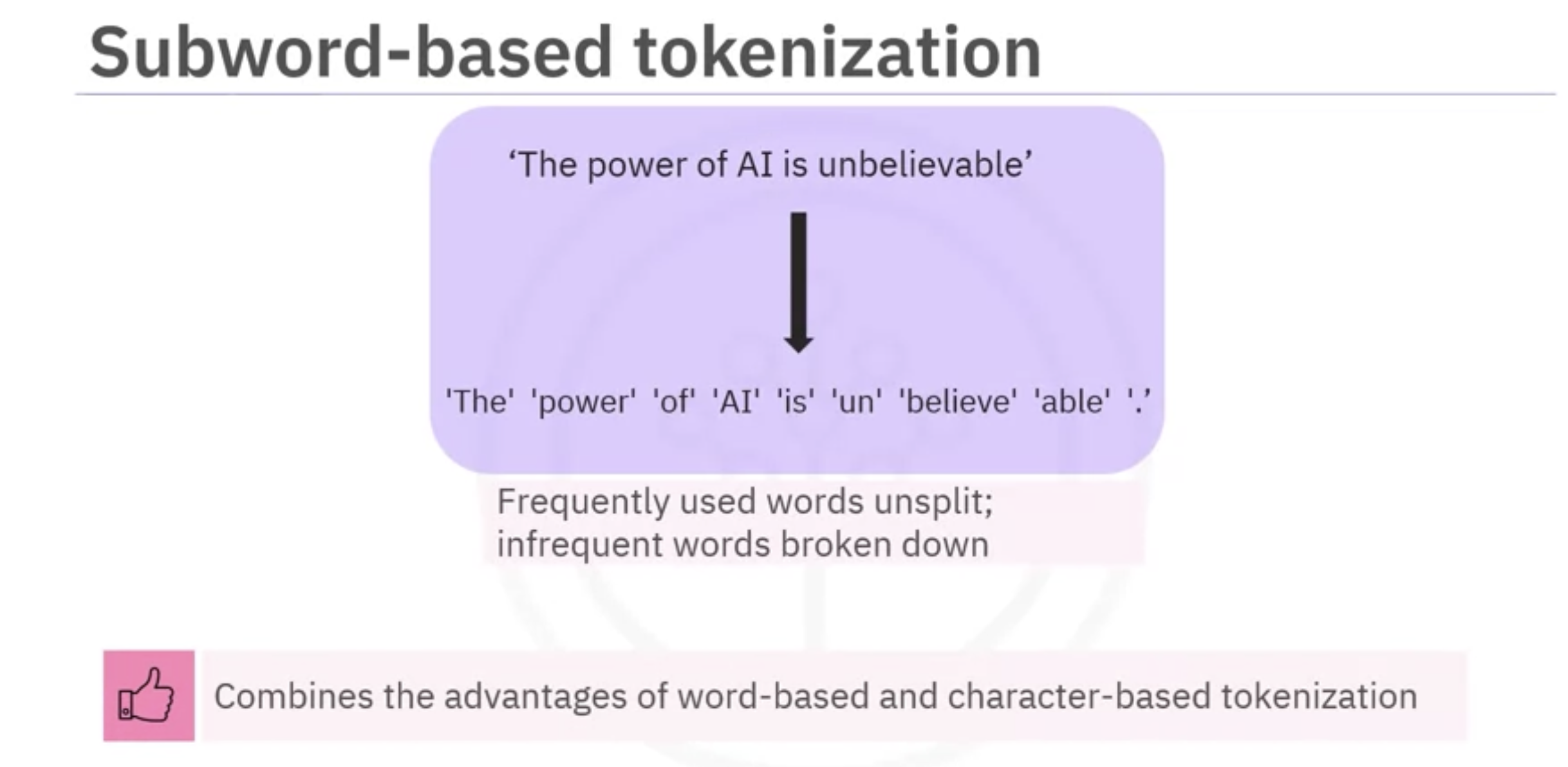
- subword based tokenization: frequently used words can remain unsplit while infrequent words are broken down into meaningful sub words. It combines the advantages of word based and character based tokenization.
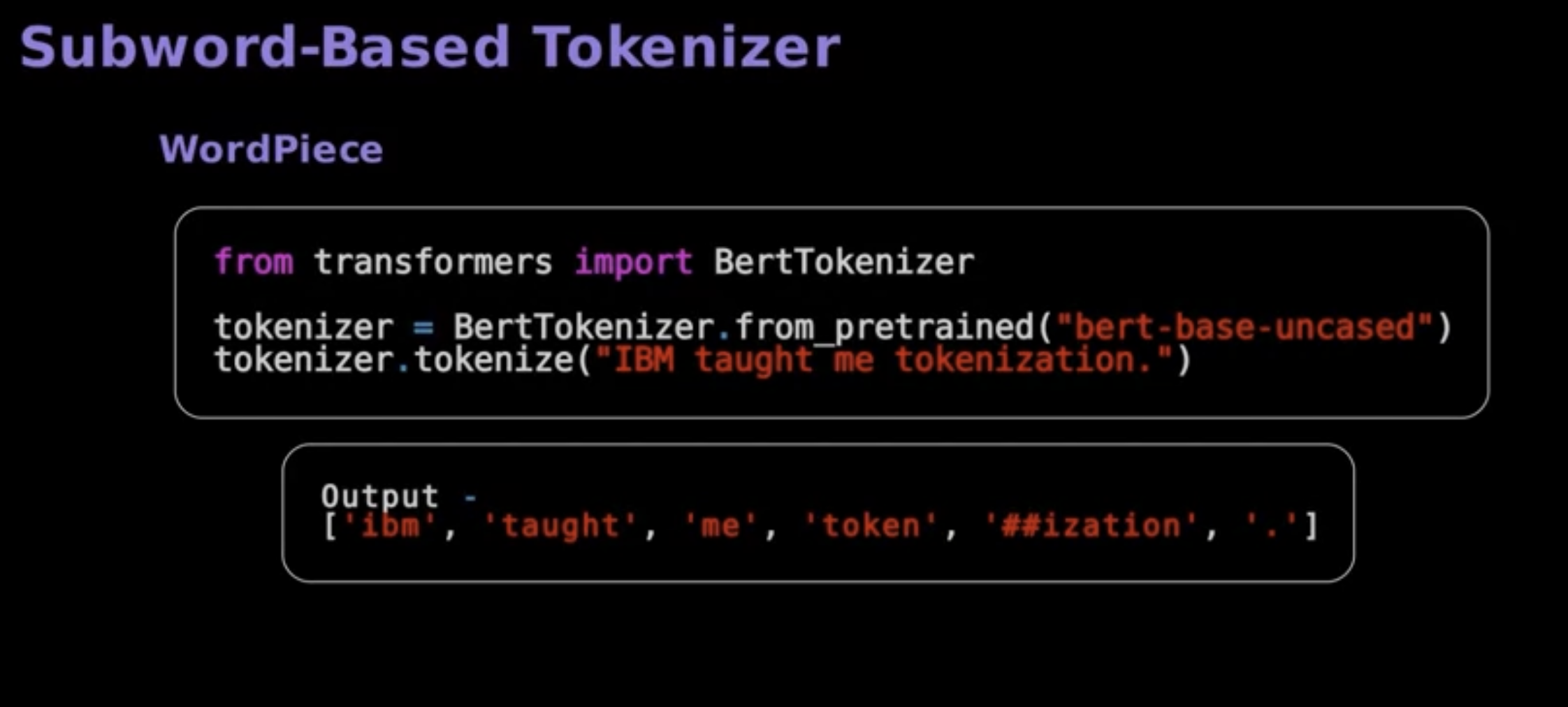
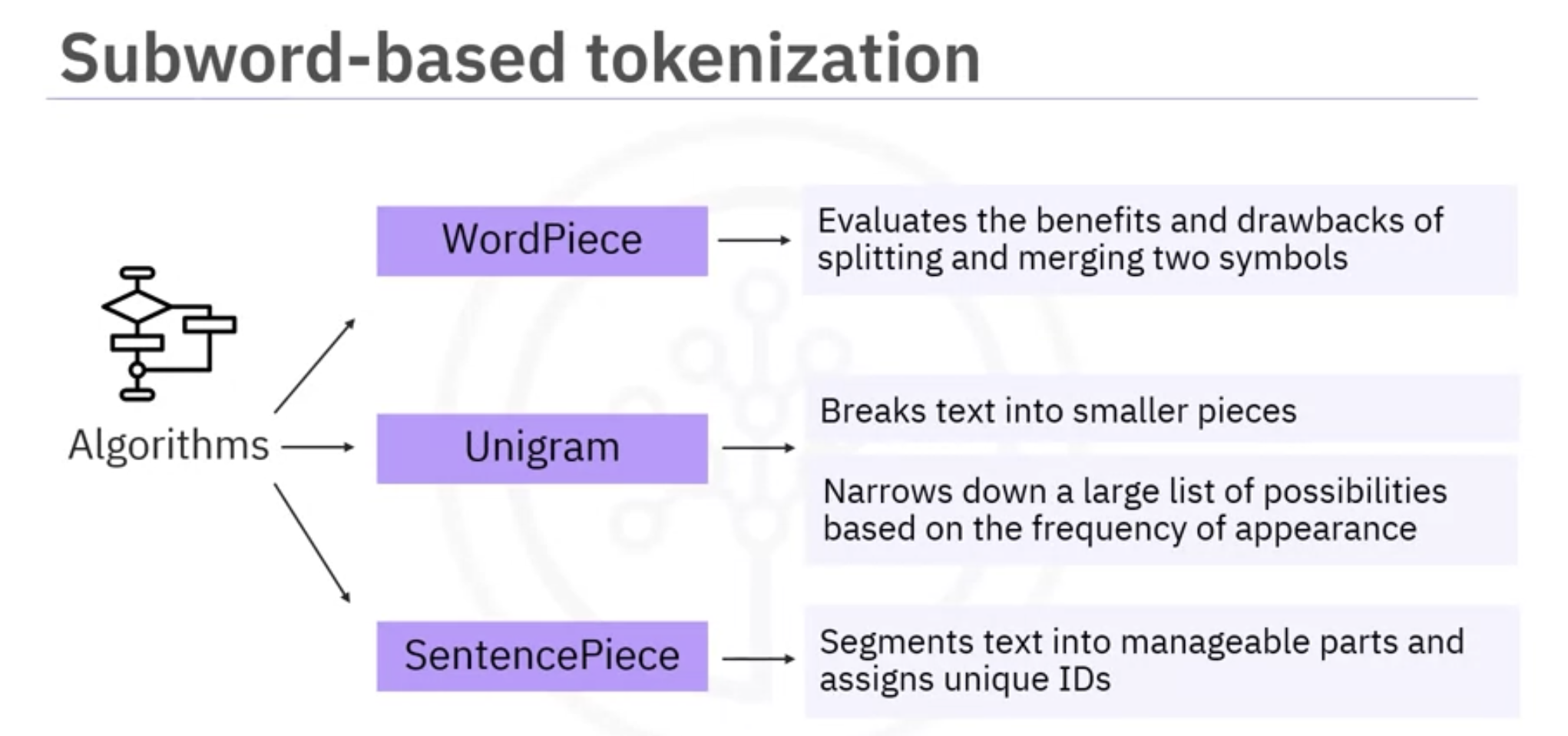
- word piece, unigram and sentence piece algorithms support subword based tokenization.
- Word piece evaluates the benefits and drawbacks of splitting and merging two symbols to ensure its decisions are valuable.
- The unigram algorithm breaks text into smaller pieces. It begins with a large list of possibilities and gradually narrows down based on how frequently they appear in the text. It’s an iterative process, gradually narrowing down possibilities.
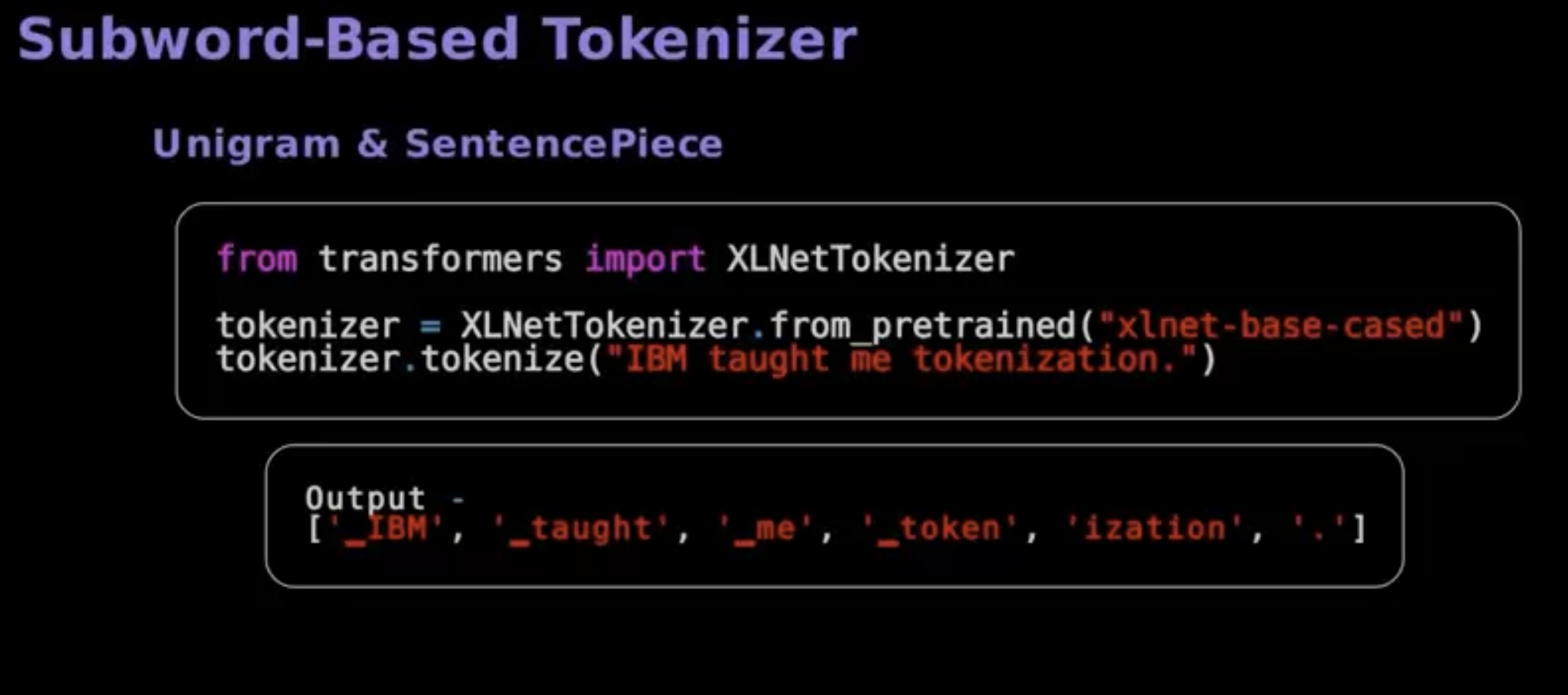
- Sentence piece segments, text into manageable parts and assigns unique IDs. Here’s an example of a tokenizer utilizing the word piece algorithm.
- word piece, unigram and sentence piece algorithms support subword based tokenization.
- Tokenization in PyTorch:
- Use the torchtext library.
- build_vocab_from_iterator function creates a vocabulary from the tokens.
- Each token is assigned a unique index.
- Special Tokens:
- Special tokens like BOS (beginning of sentence) and EOS (end of sentence) can be added.
- Padding tokens can be used to make all sentences the same length.
from torchtext.vocab import build_vocab_from_iterator
from torchtext.data.utils import get_tokenizer
# Defines a dataset
dataset = [
(1, "Introduction to NLP"),
(2, "Basics of PyTorch"),
(1, "NLP Techniques for Text Classification"),
(3, "Named Entity Recognition with PyTorch"),
(3, "Sentiment Analysis using PyTorch"),
(3, "Machine Translation with PyTorch"),
(1, "NLP Named Entity,Sentiment Analysis, Machine Translation"),
(1, "Machine Translation with NLP"),
(1, "Named Entity vs Sentiment Analysis NLP")
]
# Applies the tokenizer to the text to get the tokens as a list
tokenizer = get_tokenizer("basic_english")
print(tokenizer(dataset[0][1])) # Example of tokenizing the first text
# Takes a data iterator as input, processes text from the iterator,
# and yields the tokenized output individually
def yield_tokens(data_iter):
for _, text in data_iter:
yield tokenizer(text)
# Creates an iterator
my_iterator = yield_tokens(dataset)
# Fetches the next set of tokens from the dataset
print(next(my_iterator)) # Example of getting the next set of tokens
# Converts tokens to indices and sets "<UNK>" as the default word
# if a word is not found in the vocabulary
vocab = build_vocab_from_iterator(yield_tokens(dataset), specials=["<UNK>"])
vocab.set_default_index(vocab["<UNK>"])
# Gives a dictionary that maps words to their corresponding numerical indices
print(vocab.get_stoi())
# --- Applying the vocab object to tokens directly ---
# Takes an iterator as input and extracts the next tokenized sentence.
# Creates a list of token indices using the vocab dictionary for each token.
def get_tokenized_sentence_and_indices(iterator):
tokenized_sentence = next(iterator)
token_indices = [vocab[token] for token in tokenized_sentence]
return tokenized_sentence, token_indices
# Returns the tokenized sentences and the corresponding token indices.
# Repeats the process.
tokenized_sentence, token_indices = get_tokenized_sentence_and_indices(my_iterator)
next(my_iterator) # Move to the next sentence
# Prints the tokenized sentence and its corresponding token indices.
print("Tokenized Sentence:", tokenized_sentence)
print("Token Indices:", token_indices)
# --- Adding special tokens (BOS and EOS) ---
# Appends "<BOS>" at the beginning and "<EOS>" at the end of the
# tokenized sentences using a loop that iterates over the sentences
# in the input data
tokenizer_en = get_tokenizer('spacy', language='en_core_web_sm')
tokens = []
max_length = 0
lines = [text for _, text in dataset] # Extract text from dataset
for line in lines:
tokenized_line = tokenizer_en(line)
tokenized_line = ["<BOS>"] + tokenized_line + ["<EOS>"]
tokens.append(tokenized_line)
max_length = max(max_length, len(tokenized_line))
# --- Padding the tokenized lines ---
# Pads the tokenized lines with "<PAD>" token to ensure all sentences
# have the same length
for i in range(len(tokens)):
tokens[i] = tokens[i] + ["<PAD>"] * (max_length - len(tokens[i]))
print("Tokens with special tokens and padding:", tokens)
Cleaned up Code
from torchtext.vocab import build_vocab_from_iterator
from torchtext.data.utils import get_tokenizer
# Defines a dataset
dataset = [
(1, "Introduction to NLP"),
(2, "Basics of PyTorch"),
(1, "NLP Techniques for Text Classification"),
(3, "Named Entity Recognition with PyTorch"),
(3, "Sentiment Analysis using PyTorch"),
(3, "Machine Translation with PyTorch"),
(1, "NLP Named Entity,Sentiment Analysis, Machine Translation"),
(1, "Machine Translation with NLP"),
(1, "Named Entity vs Sentiment Analysis NLP")
]
def preprocess_and_tokenize(dataset):
"""
Tokenizes the dataset, adds special tokens (UNK, BOS, EOS), and creates a vocabulary.
Args:
dataset: A list of tuples where each tuple contains (label, text).
Returns:
A tuple containing:
- vocab: The vocabulary object.
- tokenized_data: A list of tokenized sentences with special tokens.
"""
tokenizer = get_tokenizer('spacy', language='en_core_web_sm')
def yield_tokens(data_iter):
for _, text in data_iter:
yield ["<BOS>"] + tokenizer(text) + ["<EOS>"]
# Build vocabulary with UNK token
vocab = build_vocab_from_iterator(yield_tokens(dataset), specials=["<UNK>"])
vocab.set_default_index(vocab["<UNK>"])
# Tokenize data with special tokens
tokenized_data = list(yield_tokens(dataset))
return vocab, tokenized_data
# Process the dataset
vocab, tokenized_data = preprocess_and_tokenize(dataset)
# Print the results
print("Vocabulary:", vocab.get_stoi())
print("Tokenized data:", tokenized_data)