A Study on online system design analyzes of Uber Backend
Overview:
At a high level, to approach any system design question, IK has the following recommendations.
IK’s Approach to Uber Design:
Requirements/HLD:
| Functional Requirements | HLD |
|---|---|

|
|
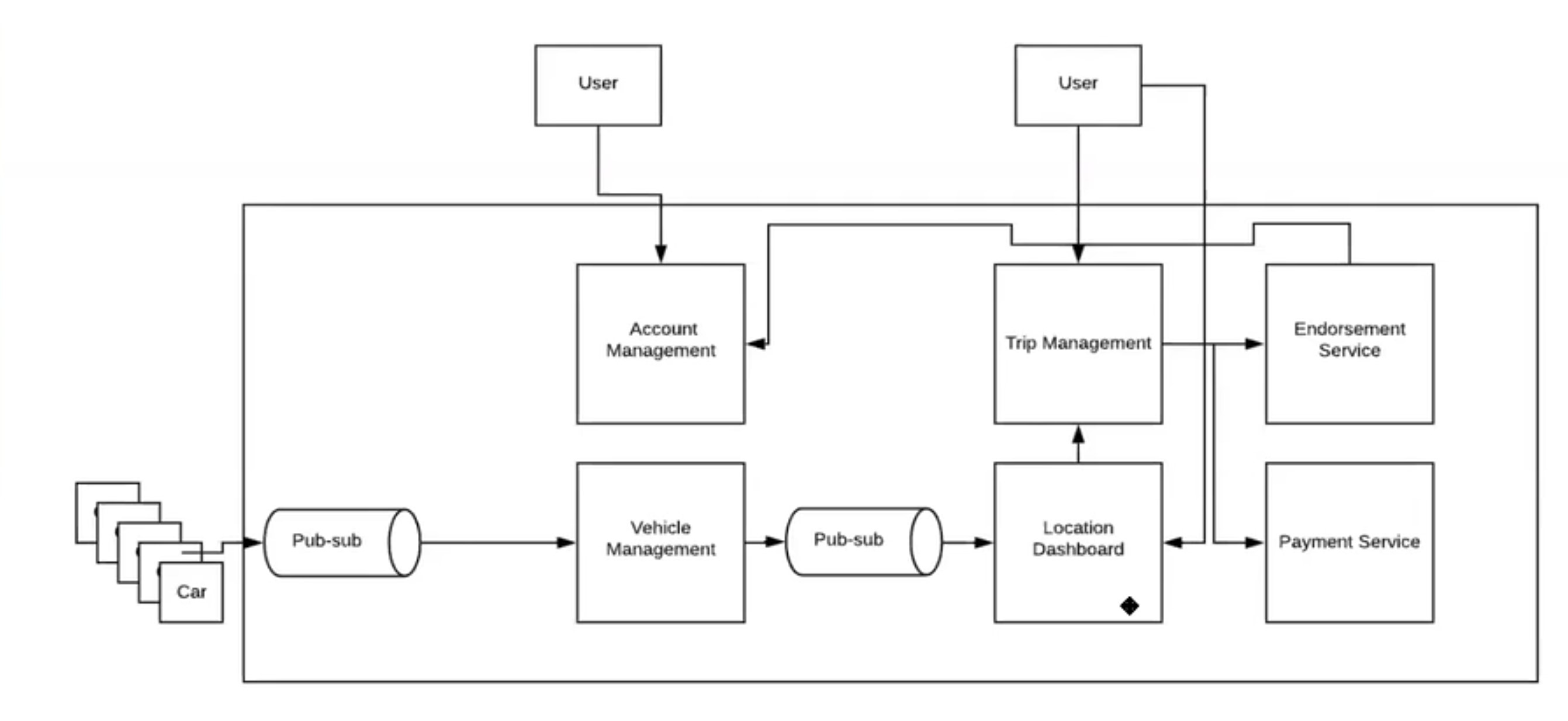
Observations/Questions:
-
None of the functional requirements are explored in depth in the depth oriented slides. There is no functional diagram either. IK says all the microservices have the generic architectural diagram
-
There is not much to comment on IK’s slides. It appears to be very sparse and just a high level reference.
Educative’s Approach to Uber Design:
Requirements/HLD:
| Functional Requirements | HLD |
|---|---|

|
|
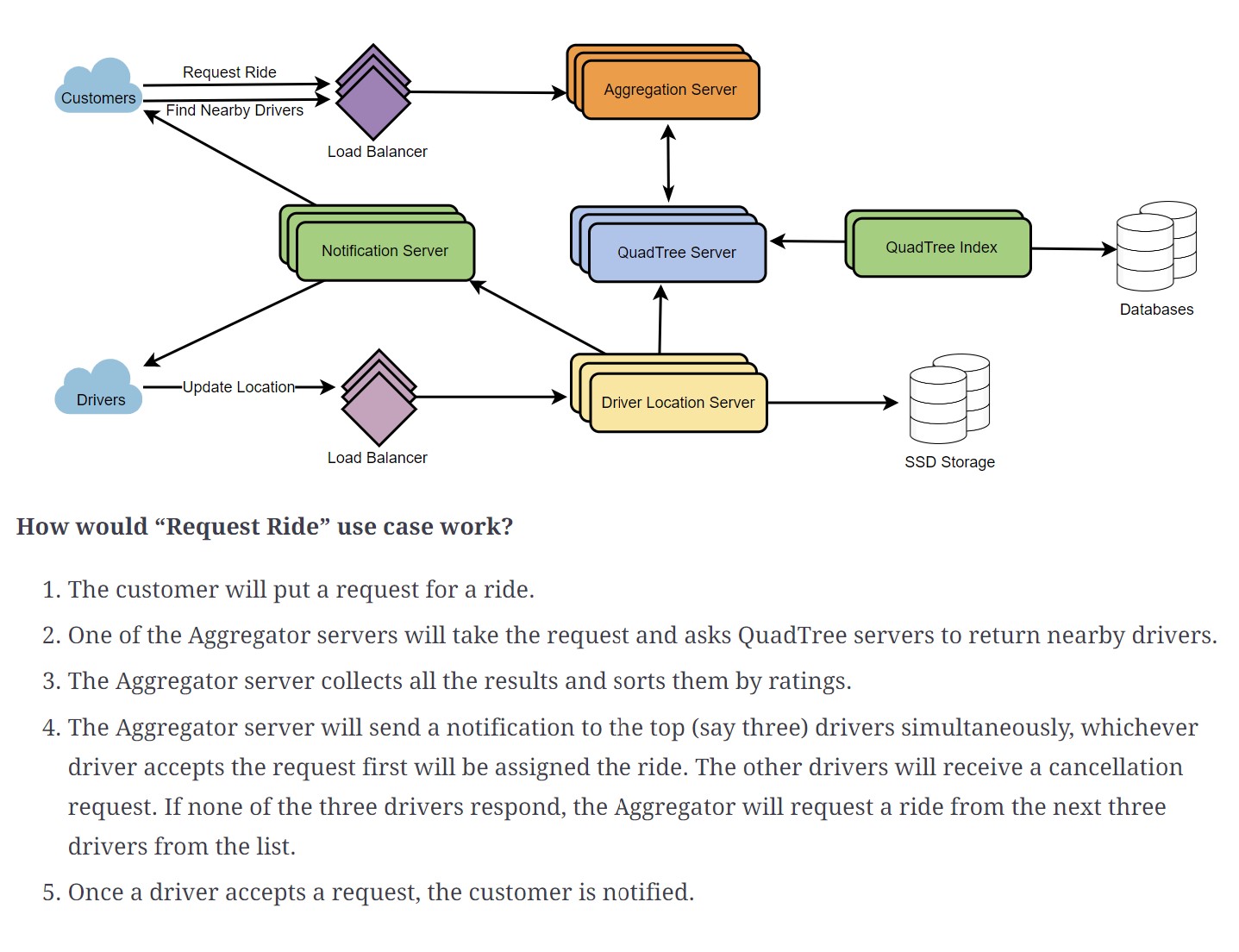
Observations/Questions:
- Q. Most of the services appear to be stand alone with no database support or cache tiers. Is this acceptable?
My Thoughts: I think we should identify if the microservice is going to read or write data and (usually this is the case) we need to identify the corresponding storage tier.
-
Q. The diagram does not reflect the last requirement ‘Upon reaching the destination, driver marks the journey complete and makes himself/herself available’
-
Q. How can we explain the statement #4 (The aggregator server will send a notification to the top 3 drivers simultaneously and continues to do this till a driver accepts…" The HLD does not show any interactions with driver or notification service.
-
Q. Given the high QPS, should not we expand the interactions between Aggregation server and QuadTree server? I presume Aggregation server uses REST API interface to talk to the Quadserver microservice.
-Q. In the functional requirements, there was no specific requirement to share ETA with the user. If this requirement is added, then can we modify the above HLD without much rework?
My Thoughts: The ETA has to come from the mapping service which in turn has to talk to the location service to get the location and then calculate the road distance to generate ETA. Can we elaborate the exact steps involved in this process? How can we modify the HLD based on this?
- What are the inputs to the mapping service?
- What are the outputs?
- For the same rider, how frequently should the ETA be updated? Does mapping service recalculate the ETA each time?
- How does the machine learning service help here? if any?
Q. How is the surge pricing handled in the above scenario?
CodeKarle’s approach to Uber Design:
Requirements/HLD:
| Functional Requirements | HLD |
|---|---|

|
|
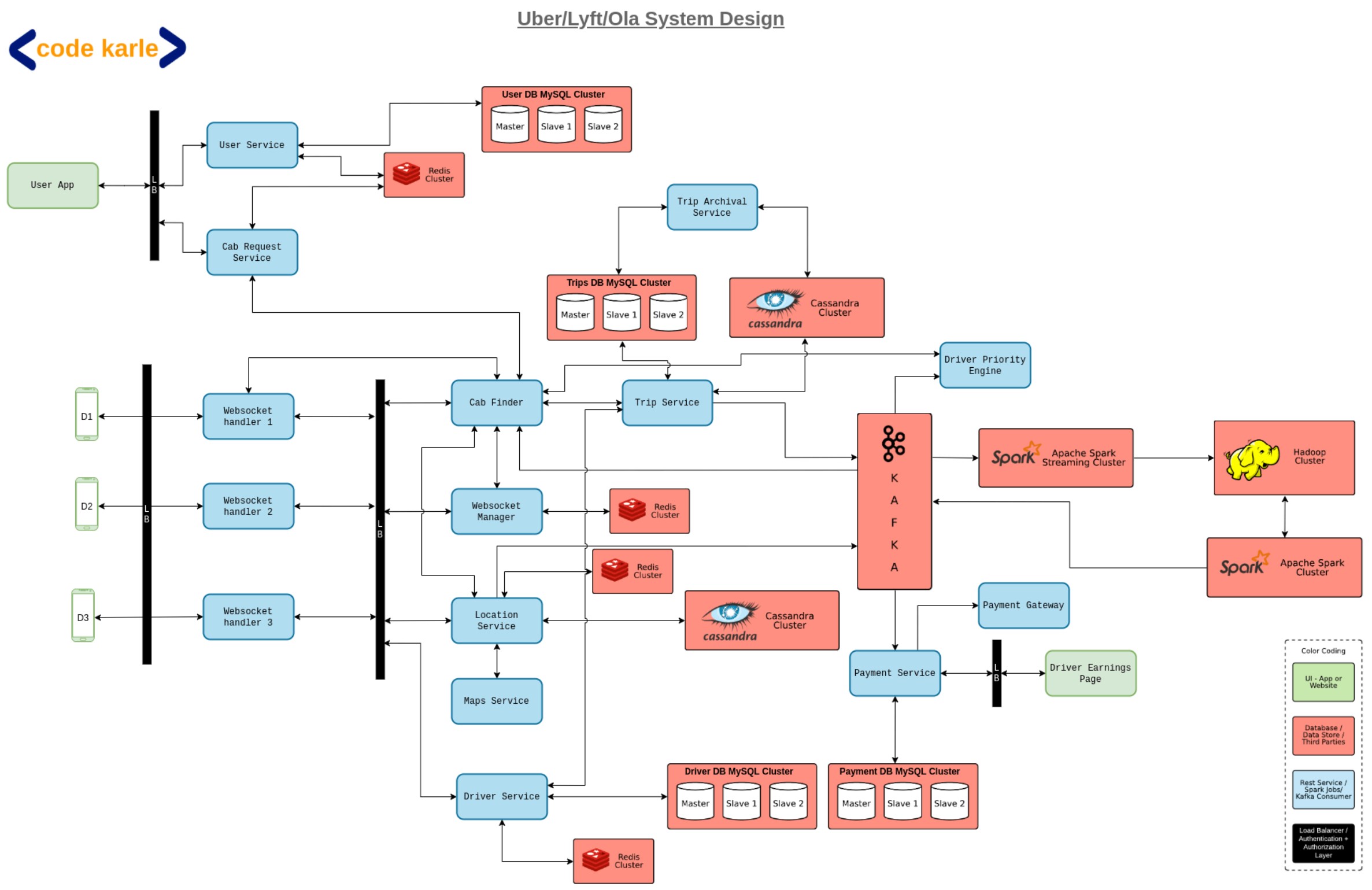
Observations/Questions:
- This is one of the most detailed analysis that I could find. The author walks through each service in detail.
- To maintain the stateful connection between riders and drivers and backends, the author suggests websockets. Uber blog has the following comments.
To provide a reliable delivery channel we had to utilize a TCP based persistent connection from the apps to the delivery service in our datacenter. For an application protocol in 2015, our options were to utilize HTTP/1.1 with long polling, Web Sockets or finally
Server-Sent events (SSE).Based on the various considerations like security, support in mobile SDKs, and binary size impact, we settled on using SSE
Narendra’s approach to Uber Design:
Requirements/HLD:
| HLD |
|---|
|
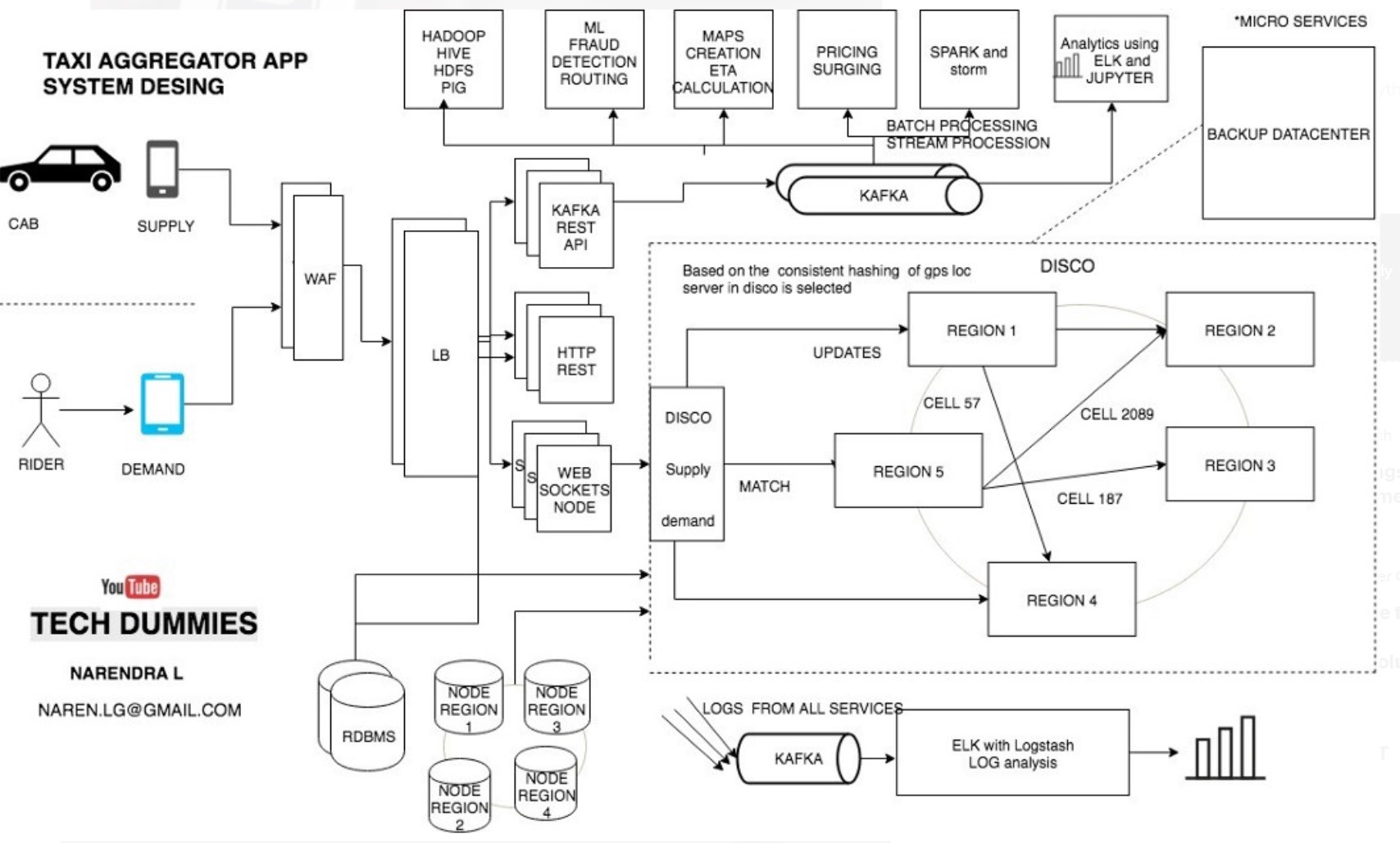
Observations/Questions:
Narendra’s design differs from what Uber has to say about its backup datacenter.
We assign cities to the geographically closest data center, but every city is backed up on a different data center in another location. This means that all of our data centers are running trips at all times; we have no notion of a “backup” data center. To provision this infrastructure, we use a mix of internal tools and Terraform.
- Narendra focuses more on the DISCO framework and not individual microservices. Though his blog has mention about many different aspects such as surge pricing, payment, analytics etc.
Summary/My TakeAways:
-
Most of the design blogs talk at very high level. There are many questions not answered which could make the difference during an interview.
-
How do microservices communciate? The standard answer is REST. Uber uses pub-sub and RPC. Uber has its variant of RPC called gRPC. There is distinction between how an edge microservice (the one that interacts with client API) interacts vs communication between internal micro services at the backend.
-
Many design blogs talk about WAF (Web Application Firewall), Load balancers and web sockets. Web sockets appear to be too costly to implement. Not sure if we should suggest it as first option. If companies with large scale data processing such as FB and Uber are not using webscokets, then why is it preferred by all designers as first choice?
-
With a polling architecture, mobile phones have to keep polling uber backend resulting in heavy load on backend server. Uber moved to push model and they have a hybrid of pull based APIs and push based APIs. From interview point of view, with push based APIs, which part of the architecture builds up bottleneck? Is it in the queue? i.e notification service struggles to push the messages to large number of clients? Is it API interface? What are the options to mitigate this if this is a valid concern?
-
There is an art of identifying the microservices which differentiates a mediocre design from a professional one. Functional requirements have to be broken down in the right way to identify the microservices. Example: Rider request for trip is typically translated as trip microservice, location service and map service. There are many more… currency service (to ensure payment is accepted in local currency), ETA service to calculate trip ETA, (which inturn uses price surge)…so identifying them or loudly thinking about them in the interview may get browny points? Right ? or may be not?
-
Most of the available system design blogs focus on app tier with limited focus on cache tier and db tier. So where do we need cache tier and where all Db tiers?
-
There is two parts to system design. Outward design that focuses on microservices, functionalities, and data/process flow between the services. The second aprt is inward design that focuses on how to scale the infrastructure. None of the blogs talk about the scalability in depth. For example, how many nodes does Uber run? do they start with so many nodes or do they dynamically add them as the demand goes up? How are partitions managed? Uber says the developer has to think about this while developing the app, include ringpop library in the app. Uber goes on to say:
Ringpop developers take ownership of the scalability and availability of their services rather than relying on external infrastructure-level solutions or systems specialists.
I do not understand this part well. If I were to develop a microservice, how can I take ownership of the scalability and availability? Do I need to tell ringpop how many nodes my service would require to run, how many db shards I require etc?
Notes from Uber talks on different aspects of Uber design:
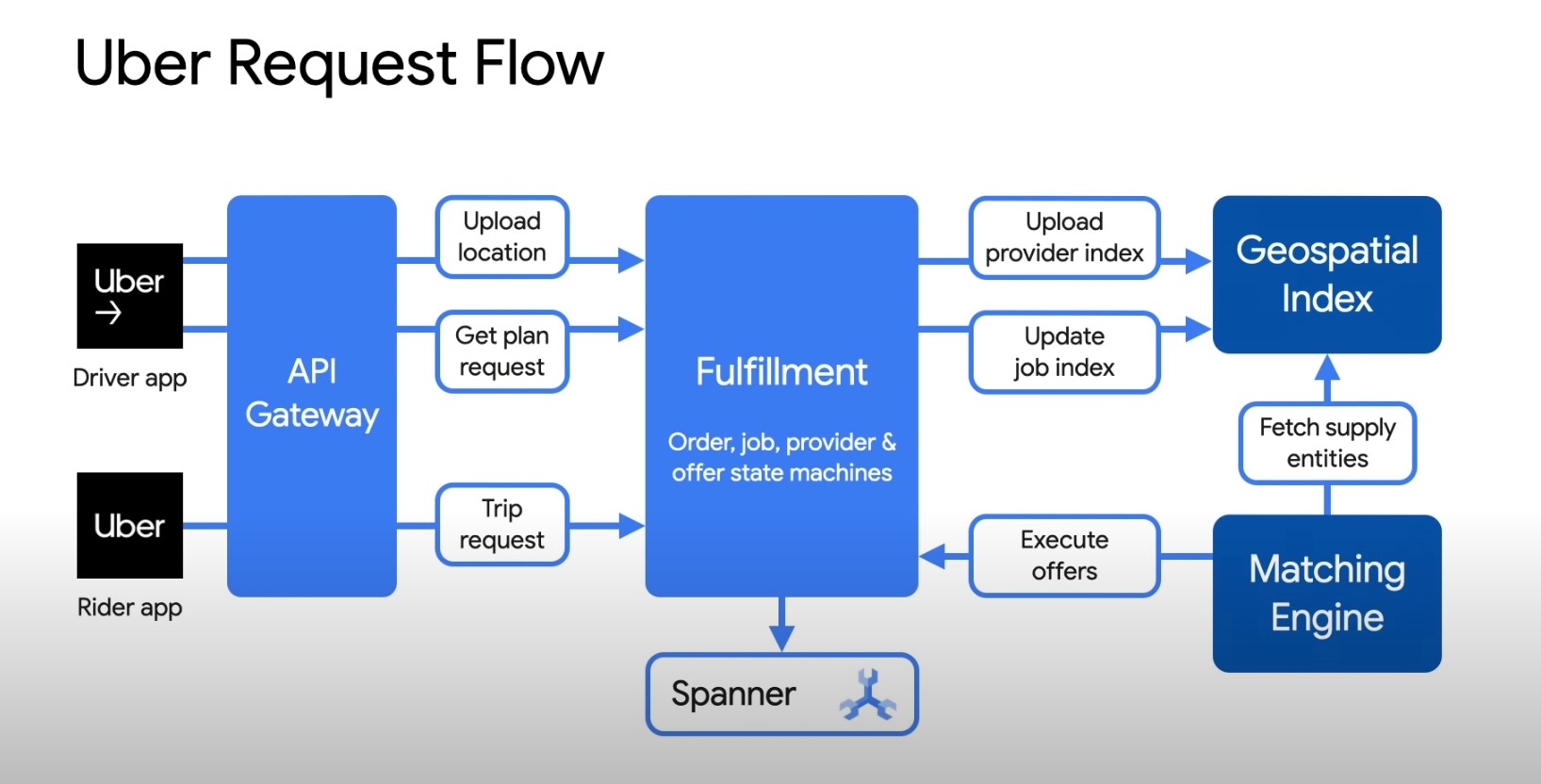
- When a consumer clicks on get taxi or get food, the app captures user’s intent and fullfill it with right set fo providers nearby.
- Fullfill model uses intent as demand and any active provider who can meet this demand as supply.
- Billions of transactions and 100s of microservices rely on the platform as source of truth.
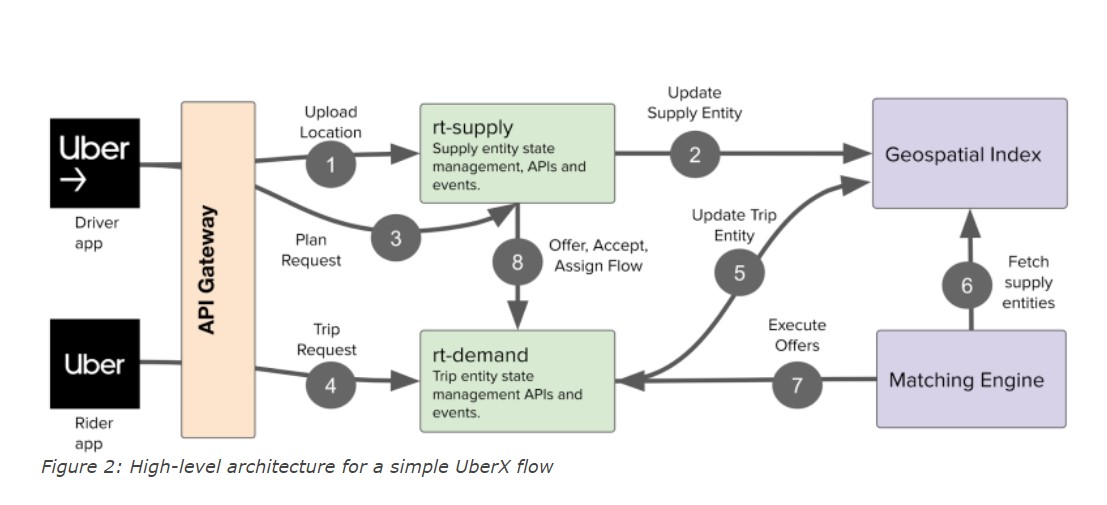
| Uber Request flow | Uber Request flow (expanding the fullfillment box) |
|---|---|
|
|
Challenges with Onprem db:
- Nosql storage engine cassandra to maintain realtime state of all fullfillment entiries on prem.
- In order to maintain some notion of seriazabiliy, on top of cassandara ringpop was used to provided individual entity level serialization.
- Cassandra in multi data center setup, it is really ahrd to guarntee low latency quoram writes with cassandra.
- Complex storage interactiosn that required required multi row and multi table writes.
- An application layer framework has to be biult to orchestrate these operations by leveraging saga pattern.
- Cassandra’s eventual consistency resulted in inconsistencies such as two drivers reaching to the same to user to pick them up. Cassandra’s approach is last-win writes.
- Horizontal Scaling Bottlenecks started showing up because of sharding in application layer in ringpop.
Saga Pattern: In a microservices architecture, it tracks all the events of distributed transacations as a sequence anddecides th rollback envetns in case of a failure.
Potential Concurrency Issues:
- A driver trying to go offline and a matching system trying to link a new trip offer to the driver results in concurrent read-modiy-writes to the sam entity.
- If a driver accepts a trip offer, trip entity, and supply entity have to be updated and this involves writing multiple entities
- If a driver accepts a batch offer with multiple trips, all the related entities need to b updated in all-or-nothing fashion.
Application and storage architecture of Uber:
- Demand and supply microservices are shared-nothing services with entities stored in cassandra.
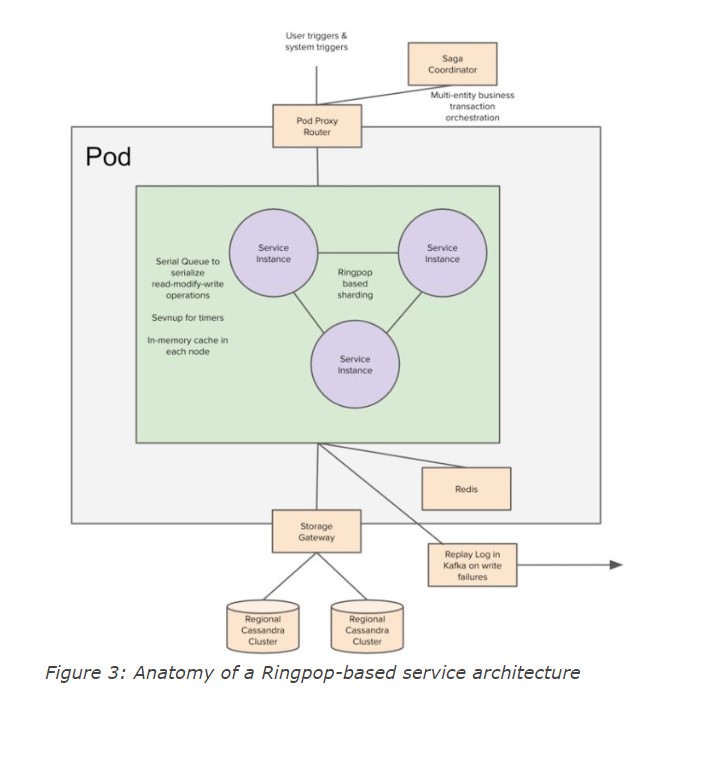
- Storage gateway provided the interface API to access KV store.
- Storage gateway connected to redis in mem cache to serve read requests and cassandra clusters for write request.
- A single application write resulted in writing to 2 distinct clusters in the same region. Each cluster has 3 replicas of data.
- Region clusters were replicated asynchronously.
- Ringpop enabled serialization of read-modify-write cycles. Each key has a unique worker and the request for a given key is forwarded to its owning worker on best-effort basis.
- To find the trips for a given rider: demand service maintained a separate table that mapped rider to trip identifiers. rt-demand is sharded using trip identifiers and all requests for a given trip identifier goes to the owning worker of the selected trip and all requests for a given rider would go to the owning worker of that rider.
- When a trip is created, trip is first saved in rider index table, then to trip table and best-effort request was sent to the rider owning worker to invalidate the cache. Source
References:
-
Uber Technology Stack:
Development Tools:
| Tool | Usage |
|---|---|
| Go | Main programming language to develop microservices |
| Hybrid Cloud Model | Cloud providers + on prem data centers |
Databases:
| Tool | Usage |
|---|---|
| MySql (SchemaLess) | Schemaless is in-house built layer on top of MYSQL for long term storage |
| Cassandra | For high availability, speed and real time performance |
| Hadoop | Distributed storage and analytics warehouse |
| Redis | For cacheing and queuing |
| Twemproxy | Scalability for cacheing layer |
| Celery | Process task queues using redis instances |
| Kafka | Logging clusters |
| ELK stack | Elastic Search, Logstash and Kibana for searching and visualizations |
| Apache Mesos and Docker | for app provisioning |
| Apache Aurora | For long running services and cron jobs |
| HAProxy | Legacy services use HAProxy to route JSON over HTTP requests. HAProxy acts as load balancer |
| NGINX server | Used as part of legacy services for front end to work with HAProxy on the backend. |
| HTTP/2, APache Thrift and TChannel | Uber is moving away from above legacy design to use HTTP/2. Google’s SPDY is deprecated and it is included in HTTP/2 which supports |
Discussion Points:
-
push vs pull: Compare kafka vs Rabbitmq
-
Cabfinder uses pull model because with push model, the threads can run out and the messages can potentially lost. With pull model, we can scale the nodes as needed.
-
When will you recommend a queue? Queue introduces latency but provides durability? Queue gets persisted into disk? There is I/O cost. can we justify?…this is the trade off to discuss
Blogs